There's no denying the rise of code development using Generative AI (GenAI, or "StackOverflow on steroids," as we sometimes call it). GitHub reports that Copilot, a GenAI coding assistant, already generates 46% of new code. While we don’t know how effective these tools will be in the long run, one thing is clear: the volume and speed of code creation is increasing. More code means more work, more cost, and more problems for CI/CD systems that can’t handle the load.
Jenkins, an open-source automation server, was the go-to CI/CD solution for many teams in the early days of DevOps. In those days, teams typically deployed 10 times a year, but today, teams may deploy more than 10 times an hour. At Buildkite, we’ve had the opportunity to help some of the most demanding software companies in the world standardize on Buildkite Pipelines, including Airbnb, Canva, Slack, Anthropic, Elastic, Block, Lyft, Pinterest, Uber, Wayfair, Wix, CultureAmp, and Rippling. For these companies, there was no way forward with their Jenkins deployment—they had experienced what we call “delivery decay,” where software builds had simply become too slow.
Here are some common issues that they faced:
- Teams hit the scale ceiling. They felt on top of things when they added their second, third, or even fourth Jenkins controller. But as they got to their 10th, 20th, or more, their infrastructure became fragile.
- Too many plugins became abandonware. Teams needed to install plugins for Jenkins to run their pipelines, but maintenance fell on them when plugins were no longer supported.
- Confusing UIs slowed productivity. The other tools in their stack had thoughtfully designed and consistent interfaces, requiring little training. Apple, for example, has teams dedicated to the UI of XCode. While often not the leading reason for switching, papercuts added up for their growing teams.
It’s human nature to stick with what is known rather than risk the unknown, which is why continuing to use Jenkins can seem like the safer option. But in reality, the productivity and maintenance cost of staying on Jenkins adds up. Companies either pay to stay on Jenkins or make the investment to switch—it’s a decision they will face sooner or later. In our experience, teams that retain the best engineering talent and build great things have chosen to leave. We want to share the journey of those companies—when to stay and when to move.
How Jenkins scales, and how it doesn’t
Scale issues in Jenkins creep up on you, with builds getting slower and slower until you realize just how much time engineers lose waiting for pipelines to complete. The reason can be found in how Jenkins is architected: it wasn’t designed for the scale needed by teams today.
Jenkins instances are collections of controllers and agents, each instance running a different type of work. Controllers are the central management points—they execute plugins, orchestrate agents to run workflows, and provide interfaces for checking build progress. They make up the CI/CD control plane and are the main cause of maintenance headaches as code contributions grow more frequent and team sizes increase.
Here’s a typical Jenkins infrastructure:
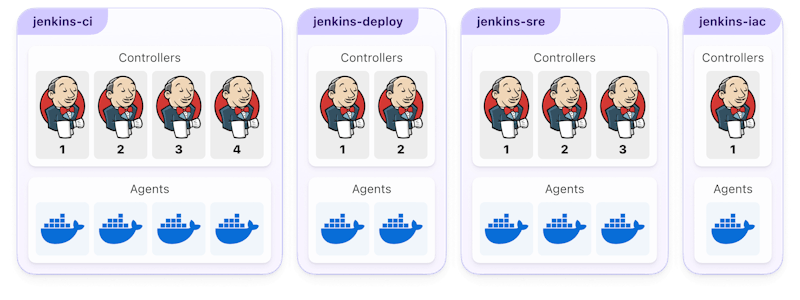
There are separate Jenkins instances dedicated to running CI pipelines, deploying changes, and various internal tasks. Inside each instance is a set of controllers to manage the workflows and agents to execute them.
Scaling a Jenkins environment is roughly linear. Add more controllers to orchestrate more work across more agents. If there’s a new type of work, add another instance—making more controllers. This generally works well, up to a point. With each new controller or instance, you need to consider:
- Ownership: Someone needs to own the maintenance and operation of a Jenkins instance to keep pipelines running.
- Upgrade process: When it’s time to update Jenkins controllers to access new features or address vulnerabilities, they need to be patched and restarted one by one. That’s fine for one or two, but when there are 20+ controllers (typical for large teams operating at global scale), that’s a few weekends’ worth of work to avoid disruption during workdays.
- High availability: Each new controller introduces more risk with right-sizing the compute, network issues, and plugin crashes (don't worry, we'll get into the plugin situation). Problems that would be a paper cut with one controller cause massive cost and downtime issues as the system grows.
The breaking point differs for each team. It might be when you add your 10th controller, or your 20th, but it will happen. Each additional controller feels like the right decision until it's not. Build times degrade as you reach limits with concurrent agents, control plane reliability halts development when controllers crash, and maintenance time increases, requiring more engineers to manage Jenkins. These costs to productivity and salaries sneak up on you.
Suddenly, the maintenance cost, stability issues, and downtime make the whole system untenable—teams hit the scale ceiling. This is when companies often consider moving to a system that better meets their needs.
If organizations haven’t run into these scale issues yet, GenAI-assisted coding means they’re likely to as the volume of code and resulting tests increase.
Why Jenkins plugins are risky
Plugins are often cited as Jenkins' best and worst feature. They offer extensive customization, with teams installing plugins to add governance, integrate with different technologies, and even replace parts of the interface. To have any degree of sophistication in Jenkins, you need to use plugins—even the CI/CD pipelines functionality comes from a suite of plugins. If you have a new idea for how to use Jenkins, there will be a plugin (or you can simply create one, if you’re skilled in JVM languages!).
Unfortunately, plugins come with maintenance costs and risks you must accept:
- Plugins can cause Jenkins to crash and become unavailable to developers.
- Plugins often carry security vulnerabilities or are abandoned.
- Jenkins upgrades and maintenance become harder and slower with more plugins.
First, plugins integrate deeply into Jenkins and can cause the whole controller to crash (not just the job currently running). Any issues in the code can lead to expensive downtime while the platform team debugs the issue and brings the instance back online.
Second, plugins are known to carry vulnerabilities, and when identified, these need to be patched quickly. Sometimes updates are available, but sometimes the plugin has been abandoned, leaving teams to write their own fix or remove the plugin. That's assuming you have engineers on the team with skills in JVM languages.
Third, upgrades and maintenance are slower as more plugins are used. Plugins must be compatible with each other and with Jenkins itself. Every new plugin means more time spent finding the Goldilocks combination of versions, and every Jenkins controller is upgraded separately. Incompatibilities can prevent Jenkins from restarting entirely. We’ve heard customer stories of routine upgrades taking over six months. Here’s a scenario which isn’t uncommon.
Plugin A has been upgraded to address security vulnerabilities and no longer supports the current version of Jenkins. The team needs to upgrade Jenkins to continue using Plugin A.
However, Plugin B has been abandoned by its authors and doesn't support the new version of Jenkins. As a result, the team needs to either upgrade Plugin B themselves or avoid upgrading Jenkins altogether.
Current Jenkins version New Jenkins version Plugin A ❌ ✅ Plugin B ✅ ❌
Each controller must be restarted to pick up plugin changes, which makes upgrades, patches, and removals disruptive. The more plugins you have, the longer the start-up time.
At some point, the tradeoff doesn't make sense. Engineers want to install new plugins enabling technologies like Kubernetes or Bazel or some new workflow but are stopped from doing so. That's typically when platform teams can't support engineers or engineering teams can't configure Jenkins the way they need to, which ultimately limits how useful Jenkins can actually be.
Outdated UI impacts developer experience and productivity
When companies track developer experience through periodic surveys, Jenkins consistently appears near the top of the complaints. Why? The Jenkins UI is outdated, often frustrates developers, and impacts productivity. While this may not be the leading reason companies move off Jenkins, it comes up every time.
UIs can draw polarizing responses, and the same is true with Jenkins. Seasoned pros have learned to become efficient, but newer users express frustration with the complexity and sprawl of features (not entirely surprising for a community-created tool with roots back to 2004). However, the Jenkins UI and logs make it hard to actually triage and resolve issues with code. Considering that a failed build can cause pipelines to become blocked (and stall developers), the longer it takes to address the problem, the bigger the impact on the team.
Elastic, who switched from Jenkins to Buildkite Pipelines, was able to significantly streamline CI error resolution, which turned CI from the least-liked system in its developer experience surveys to the most-liked. Elastic also accelerated their build times by 70%.
Buildkite’s approach
In the era of AI-assisted development, handling the increased volume and frequency of code changes requires a robust delivery platform. Buildkite’s customers, with some of the most sophisticated engineering teams in the world, have standardized on Buildkite Pipelines to ship high volumes of code at high speed, keeping developers productive and happy. Buildkite has spent a long time writing great CI/CD software that scales to support the volume and velocity of AI-assisted coding, not just riffing on the classics.
Buildkite gives teams:
- Scale for GenAI workloads: Buildkite's SaaS control plane offers virtually unlimited scaling, supported by a 99.95% uptime SLA. Teams can run massive parallelization and highly-tuned pipelines, reducing build times significantly.
- Dynamic pipelines: Buildkite’s dynamic pipelines mean steps can be generated at runtime and written in any language. Tailor each build to the code change and take advantage of Buildkite’s primitives to assemble the best CI/CD process for your team.
- Plugins that enable your engineers: Plugins let teams use new tools and approaches in every pipeline. Platform teams can rest easy since plugins are scoped to pipeline steps and can’t crash the control plane, enabling flexibility without the risk-reward tradeoff.
- Security and governance: Isolated clusters provide secure boundaries for compliance, self-hosted agents keep you in full control of the build environment, and hooks enforce consistent practices across the pipeline lifecycle.
Uber scales up 100,000 concurrent agents to blast through 1,000 daily commits on their monorepo codebase, comprising over 500,000 files and 50 million lines of code. Hear from Uber engineers Xiaoyang and Tyler how migrating from Jenkins to Buildkite accelerated their monorepo software delivery in the following webinar.
How Uber accelerates software delivery with fast, reliable, and scalable CI
Register to watch the webinar

- Recorded on
- February 11, 2024
- Length
- 24 minutes
Conclusion
Jenkins helped many engineering teams start their CI/CD journey, but building great software requires great engineers, who require great tooling. Why leave your developers to battle with a CI/CD tool not designed for today’s needs?
Teams require tools that can scale to meet the demands of software delivery in the GenAI era—especially as AI code assistants increase the volume and frequency of code changes. Buildkite’s platform is designed for this new reality. Unlimited scalability across hundreds of thousands of agents. Rich customization to craft finely-tuned pipelines. Trusted stability for platform teams. Consider if it’s time to make the switch and future-proof your software delivery today.
Buildkite Pipelines is a CI/CD tool designed for developer happiness. Easily follow and decipher logs, get observability into key build metrics, and tune for enterprise-grade speed, scale, and security. Every new signup gets a free trial to test out the key features. See Buildkite Pipelines to learn more.